O Problema da Aprendizagem
Prefacio
A proposta desta série de posts é apresentar, de forma clara e acessível, os fundamentos matemáticos que tornam o aprendizado de máquina (Machine Learning) possível. Fundamentos que muitas vezes ficam de fora dos cursos online ou aparecem apenas de maneira superficial.
Minha inspiração vem do trabalho de David F. Rogers e J. Alan Adams no livro Mathematical Elements for Computer Graphics: uma obra que tornou conceitos matemáticos complexos compreensíveis para programadores e estudantes. Quero fazer algo semelhante aqui, mas voltado para o aprendizado de máquina.
Todos os posts serão escritos em português (pt-BR). Embora exista bastante material em inglês espalhado pela internet, ainda há poucos recursos em português que combinem rigor, clareza e aprofundamento matemático.
No final de cada post, você encontrará uma seção de referências com todas as fontes utilizadas, para que possa consultar o material original e explorar exemplos adicionais. Os livros que servirão de base para esta série são principalmente:
-
Learning from Data — Yaser S. Abu-Mostafa, Malik Magdon-Ismail e Hsuan-Tien Lin
-
Pattern Recognition and Machine Learning — Christopher M. Bishop
-
Applied Multivariate Statistical Analysis — Wolfgang Härdle e Leopold Simar
O objetivo é que esta série sirva como um guia para quem deseja compreender não apenas “como usar” técnicas de Machine Learning, mas por que elas funcionam.
O Problema da Aprendizagem
Considere o seguinte cenário: é sábado à noite e cada pessoa da sua casa quer algo diferente. Você quer pizza, seu irmão quer um açaí gigante e sua mãe quer comida japonesa.
Agora imagine conectar cada usuário ao restaurante ideal — mesmo quando são cozinhas diferentes, com preços diferentes, tempos de entrega diferentes e preferências que mudam o tempo todo. Quanto tempo o pedido deve levar? Qual restaurante é a melhor opção para cada pessoa? Esses são exatamente os desafios que a maior foodtech da América Latina, o iFood, resolve todos os dias.
Como mencionei no início, usuários e restaurantes têm características únicas — e ambas mudam constantemente. O “melhor” restaurante não é apenas o que serve a melhor comida. Ele também precisa ter o preço certo, o tempo de entrega adequado e, quem sabe, até uma promoção especial naquele momento.
O grande desafio é identificar, a cada instante, qual é a melhor oferta para aquele cliente, naquele contexto específico. Para isso, o sistema de recomendação do iFood é estruturado em quatro pilares principais:
- Perfil do cliente: quanto ela pode pagar? Quão ativa é essa usuária? Que culinárias ela mais pede?
- Contexto: como o comportamento muda aos fins de semana? Em datas especiais? Em uma determinada localização?
- Jornada do cliente: se um usuário pediu pizza ontem, o que faz sentido recomendar hoje?
- Perfil dos pratos: quais tags definem cada prato? Prazer, saudabilidade, rapidez, valor calórico, risco de alergias, etc.
E é justamente aqui que entra o poder do learning from data. Em vez de programar manualmente todas essas regras — o que seria impossível — o sistema aprende sozinho, a partir dos dados de pedidos anteriores. Ele descobre padrões complexos que conectam cada cliente, cada prato e cada contexto, fazendo uma “engenharia reversa” das preferências reais das pessoas. Caso você queria saber mais sobre o sistema de recomendação do ifood, leia o post [1] que foi escrito pela Julia Tessler no Medium.
Componentes da Aprendizagem
O sistema de recomendação do iFood ilustra de forma clara o que significa aprender a partir de dados — assim como muitas outras aplicações em domínios totalmente distintos. Para compreender melhor os elementos comuns presentes em qualquer problema de aprendizado, utilizarei esse cenário ao longo da explicação. Ele servirá como metáfora para apresentar, de maneira intuitiva, cada componente essencial do processo de learning from data.
No livro Learning from Data, o professor Yaser Abu-Mostafa adota o exemplo da análise de solicitação de cartão de crédito para desempenhar esse mesmo papel. Caso você deseje conferir como ele usa essa metáfora, basta consultar a subseção 1.1.1 Components of Learning [2].
Antes de prosseguir, vale destacar as condições fundamentais que caracterizam um problema de aprendizado de máquina. Em linhas gerais, elas podem ser resumidas em três pontos:
-
Existencia um padrão;
-
Esse padrão não é diretamente acessível — não há uma fórmula ou método matemático fechado capaz de resolvê-lo;
-
Existem dados a partir dos quais podemos tentar inferir esse padrão.
Se o problema que você está estudando não satisfaz essas três condições, então ele simplesmente não se enquadra como um problema de aprendizado de máquina
Bom, vamos agora formalizar matematicamente os componentes principais de um problema de aprendizado. Primeiro, temos a entrada $x$ , que representa as informações disponíveis sobre um usuário naquele momento (por exemplo: horário do dia, histórico de pedidos, localização, categoria preferida etc.). Existe também uma função alvo (target function) $f: X \rightarrow Y$. No contexto da metáfora do iFood, $f$ representa a escolha ideal do usuário — isto é, a função que saberia exatamente qual restaurante o usuário escolheria em cada situação. O conjunto $X$ é o espaço de entrada (input space), contendo todas as possíveis combinações de características $X$.
O conjunto $Y$ é o espaço de saída (output space), que representa todas as recomendações possíveis (por exemplo, um restaurante ou um conjunto ranqueado de restaurantes). Também temos o conjunto de dados $D = {(x_n, y_n)}_{n=1}^N$, composto por pares entrada–saída, onde cada $y_n = f(x_n)$ é a escolha que o usuário realmente fez naquele contexto. Por fim, temos o algoritmo de aprendizado (learning algorithm), cujo objetivo é encontrar uma função $g$ tal que $g : X \rightarrow Y$ seja uma boa aproximação de $f$. O algoritmo não pode escolher qualquer função possível — ele deve escolher dentro de um conjunto limitado de candidatos, chamado conjunto de hipóteses, $H$. Assim como o iFood não mostra todos os restaurantes do mundo, mas apenas um subconjunto disponível e relevante, o algoritmo também escolhe sua hipótese apenas dentro do “cardápio” oferecido por $H$. A figura abaixo ilustra os compontes de aprendizagem.
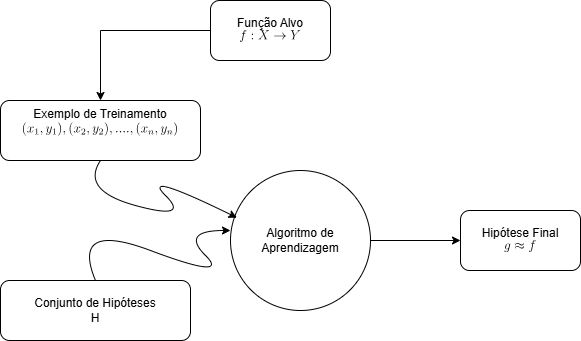
Resumo dos componentes:
- Entrada: $ x $ (características do usuário)
- Saída: $ y $ (conjunto de todas as recomendações possíveis)
- Função alvo: $ f: X \rightarrow Y $ (função desconhecida que define o padrão a ser aprendido)
- Dados: $ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n) $ (histórico de interações do cliente)
- Hipótese: $ g: X \rightarrow Y $ (resposta do modelo de aprendizado de máquina), com $g \in H $ (conjunto de hipóteses)
Embora o sistema de recomendação do iFood seja uma excelente metáfora para entendermos o que significa aprender a partir de dados, ele não é adequado para ilustrar alguns dos modelos matemáticos mais básicos que estudaremos a seguir — como o perceptron. Esses modelos assumem um problema de classificação binária, simples e linearmente separável, algo que não corresponde à natureza do problema de recomendação.
Por esse motivo, seguindo a mesma estratégia adotada pelo professor Yaser Abu-Mostafa, na próxima seção utilizaremos um exemplo mais simples e apropriado: o problema de aprovação de crédito — assim como outros exemplos clássicos, como a classificação de e-mails em spam ou não-spam.
Modelo Linear Bem Simples
Vamos considerar um problema de classificação binária simples. O espaço de entrada será $X = \mathbb{R}^d,$ onde cada vetor $ x \in \mathbb{R}^d $ representa os atributos de um solicitante de crédito (por exemplo: renda, idade, histórico financeiro, etc.). O espaço de saída será $Y = {+1, -1},$ onde ( +1 ) indica que o crédito é aprovado e ( -1 ) indica que o crédito é negado.
O conjunto de hipóteses $ H $ será composto por funções lineares que atribuem um peso a cada atributo do vetor de entrada. Cada hipótese $ h \in H $ é definida por um vetor de pesos $ w = (w_1, \dots, w_d) $ e um termo de viés (bias) $ b $.
O modelo calcula uma espécie de pontuação de crédito por meio de uma combinação linear dos atributos, e a decisão final é obtida comparando essa pontuação a um limiar. Essa regra de decisão pode ser escrita como: $$ h(x) = \text{sign}\left((\sum_{i=1}^{d} w_i x_i) - b\right) $$
Se o valor da soma ponderada ultrapassar o limiar (isto é, o argumento do sinal for positivo), o crédito é aprovado; caso contrário, ele é negado. $$ \text{Se} \ \sum_{i=1}^d w_ix_i > threshold, \ \text{Crédito Aprovado} \newline \text{Se} \ \sum_{i=1}^d w_ix_i < threshold, \ \text{Crédito Negado} $$
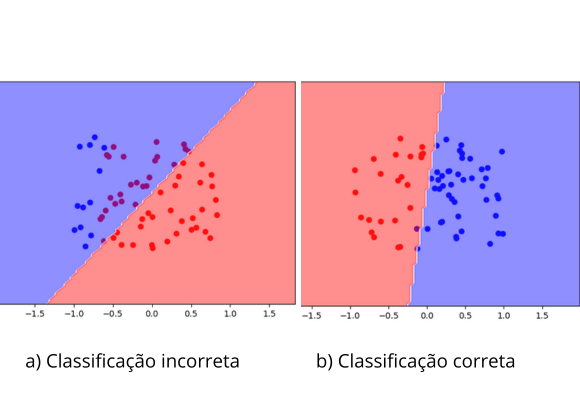
A imagem acima ilustra a classificação dos dados utilizando o Perceptron. Os dados são linearmente separáveis e pertencem a um espaço bidimensional ($\mathbb{R}^2$). Em (a), o perceptron ainda classifica incorretamente alguns pontos de treino (pontos vermelhos na região azul). Em (b), temos a hipótese final, que consegue separar corretamente todos os dados de treino.
Para simplificar a formulação do perceptron, podemos incorporar o termo de viés (bias) $b$ ao vetor de pesos $w$, definindo $w_0 = b$. Assim, o vetor de pesos passa a ser: $w = [w_0, w_1, \dots, w_d].$ De forma análoga, modificamos o vetor de entrada para incluir um termo constante $x_0 = 1$, resultando em: $x = [x_0, x_1, \dots, x_d].$
Com essa notação, a equação vetorial da hipótese $h(x)$ pode ser escrita de forma compacta como: $$ h(x) = \text{sign}(w^T x). $$
Perceptron Learning Algorithm (PLA)
Como o algoritmo do perceptron funciona? Como ele consegue encontrar um vetor de pesos $w$ capaz de classificar corretamente os dados de treino, isto é, tal que $h(x_n) = y_n$? A ideia do PLA é bastante simples. O algoritmo começa com um vetor de pesos inicial $w(0)$ e, a cada iteração $t = 0, 1, 2, \dots$, atualiza esse vetor sempre que encontra um ponto de treino classificado incorretamente.
Em cada iteração, o algoritmo seleciona um exemplo $(x_n, y_n)$ do conjunto de dados que esteja mal classificado, ou seja, tal que: $$ y_n , (w^T x_n) < 0. $$
Quando isso acontece, os pesos são atualizados segundo a regra: $$ w(t+1) = w(t) + y_n x_n. $$
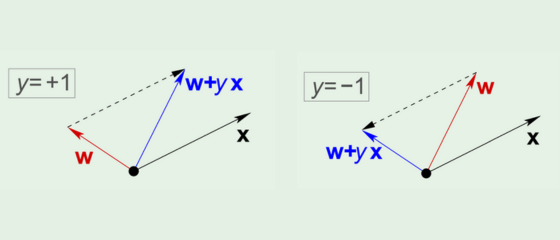
Geometricamente, essa atualização move o vetor $w$ na direção de $x_n$ quando $y_n = +1$, e na direção oposta quando $y_n = -1$. Isso faz com que a fronteira de decisão seja ajustada de forma a aumentar a chance de classificar corretamente esse ponto em iterações futuras. Como mostrada na imagem abaixo.
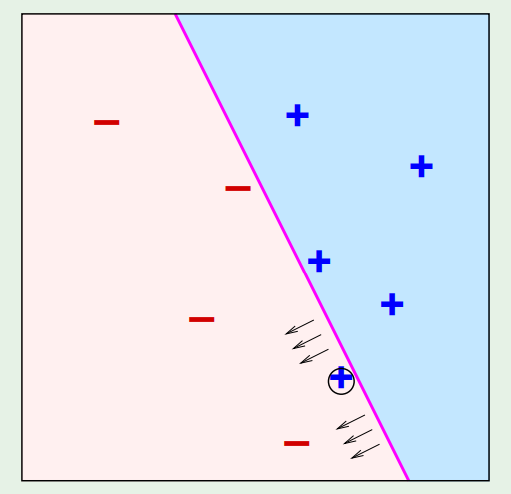
Em termos geométricos, um erro ocorre quando o ângulo entre $w$ e $x_n$ resulta em um produto interno cujo sinal é oposto ao rótulo verdadeiro $y_n$. A regra de atualização corrige essa situação deslocando o hiperplano na direção adequada, como ilustrado na figura abaixo.
O código em python abaixo apresenta um algoritmo simples do perceptron com base no que foi apresentado até agora.
def PLA(X, Y):
#w = os pesos
w = [0, 0, 0]
# numero de iterações
ite = 0
#Lista de pontos
listaPCI = X.copy()
y_PCI = Y.copy()
while(len(listaPCI) > 0):
ite += 1
i = pegarPonto(len(listaPCI))
w[0] = w[0] + y_PCI[i]
w[1] = w[1] + y_PCI[i]*listaPCI[i][0]
w[2] = w[2] + y_PCI[i]*listaPCI[i][1]
listaPCI, y_PCI = cria_listaPCI(X, Y, w)
return ite, w
No proximo post vou falar de como o aprendizado é possivel matematicamente falando, qual é a relação entre a amostra e a população, Desigualdade de Hoeffding etc. Como todo esse conhecimento matematico se conecta com aprendizado de maquina(machine learning).